False sharing is a pitfall appears in parallel codes unintentionally. If two CPU cores access independent but memory-neighboring variables, the cache does not function because the two variables locate in the same cache line and both cores have to access lower memory hierarchy to ensure memory coherence. If CPU core 0 read variable a and then update it, CPU core 1 have to invalidate the cache line where b locates and access it from either remote cores or lower hierarchy. The minimal unit of CPU reading is somewhat like write amplification in flash and SSD.
Experiment
To verify the conclusion, I’ve conducted some experiments. Codes are available at Github. Google benchmark framework is used to measure the elapsed time.
First, std::thread is exploited to simulate tasks executed in different CPU cores. In each task, the CPU fetches one variable and update several times. Note that the compiler may do some optimizations so the variable will reside in register. To avoid that, std::atomic is used to make use of memory consistency insurance.
void work(std::atomic<uint32_t>& a) {
for (size_t i = 0; i < repeat_times; ++i) {
a++;
}
}
static void BM_direct_sharing(benchmark::State& state) {
while (state.KeepRunning()) {
std::atomic<uint32_t> a;
a = 0;
std::vector<std::thread> threads;
for (size_t i = 0; i < n_threads; ++i) {
threads.emplace_back([&]() { work(a); });
}
for (size_t i = 0; i < n_threads; ++i) {
threads[i].join();
}
}
}
BENCHMARK(BM_direct_sharing)->UseRealTime()->Unit(benchmark::kMillisecond);
static void BM_false_sharing(benchmark::State& state) {
while (state.KeepRunning()) {
std::atomic<uint32_t> a, b, c, d;
a = 0;
b = 0;
c = 0;
d = 0;
std::vector<std::thread> threads;
threads.emplace_back([&]() { work(a); });
threads.emplace_back([&]() { work(b); });
threads.emplace_back([&]() { work(c); });
threads.emplace_back([&]() { work(d); });
for (size_t i = 0; i < n_threads; ++i) {
threads[i].join();
}
}
}
BENCHMARK(BM_false_sharing)->UseRealTime()->Unit(benchmark::kMillisecond);In BM_direct_sharing, all 4 threads share the same variable a, while in BM_false_sharing, the 4 threads seems to share no data between each other. Since sizeof(std::atmoc<uint32_t>) = 4, the 4 neighboring variable a, b, c, and d will locate in the same cache line (whose size is normally 64B in modern processors). As mentioned above, the CPU cores have to bypass the nearest cache to access the data.
So how can we avoid false sharing? Intuitively, we should avoid the neighboring variables being allocated in the same cache line. Therefore, we can append some useless bits behind the significant bits of each variable (padding), or force each variable to be aligned with cache line border (alignment). Here I use the latter.
// Avoid false sharing by exploiting memory align
static void BM_no_sharing(benchmark::State& state) {
while (state.KeepRunning()) {
AlignedType a, b, c, d;
std::vector<std::thread> threads;
threads.emplace_back([&]() { work(a.val); });
threads.emplace_back([&]() { work(b.val); });
threads.emplace_back([&]() { work(c.val); });
threads.emplace_back([&]() { work(d.val); });
for (size_t i = 0; i < n_threads; ++i) {
threads[i].join();
}
}
}
BENCHMARK(BM_no_sharing)->UseRealTime()->Unit(benchmark::kMillisecond);Results
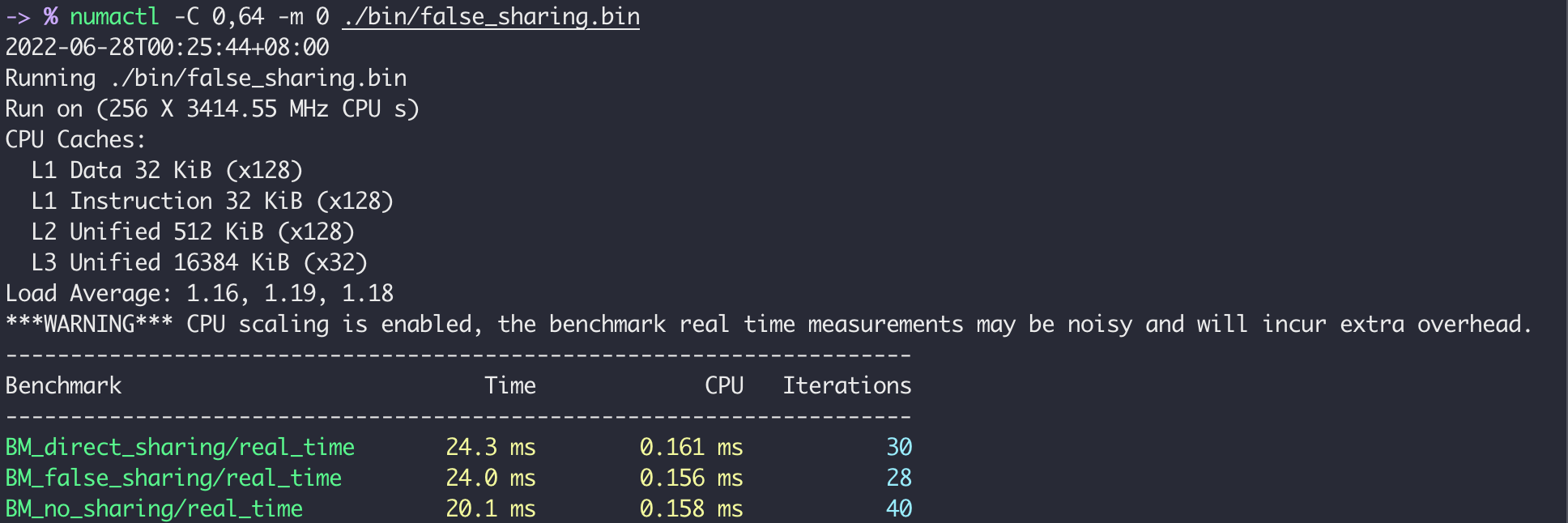
 The elapsed times illustrated above tell us the false sharing is acting as the 4 thread share the same variable (that’s why we call it “false sharing”).
The elapsed times illustrated above tell us the false sharing is acting as the 4 thread share the same variable (that’s why we call it “false sharing”).
NUMA-aware False Sharing
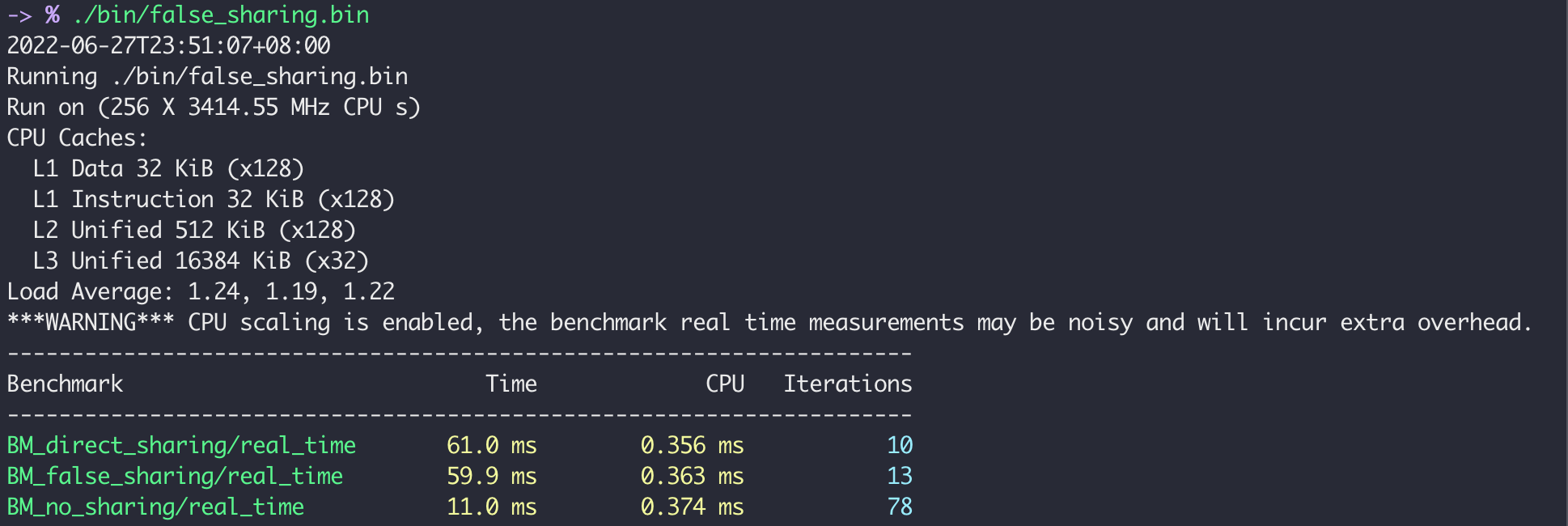
Moreover, I conduct some additional experiments using numactl to explore the impact of hyper-threading (HT). In my environment, a physical simulators two logical cores, and both logical cores share the same L1 and L2 cache (see details from numactl -H). If two threads running on two HTs spawned from one physical core, then the performance degradation can be alleviated since the two cores share the same cache and don’t need to invalidate the cache line. The result below supports this hypothesis.
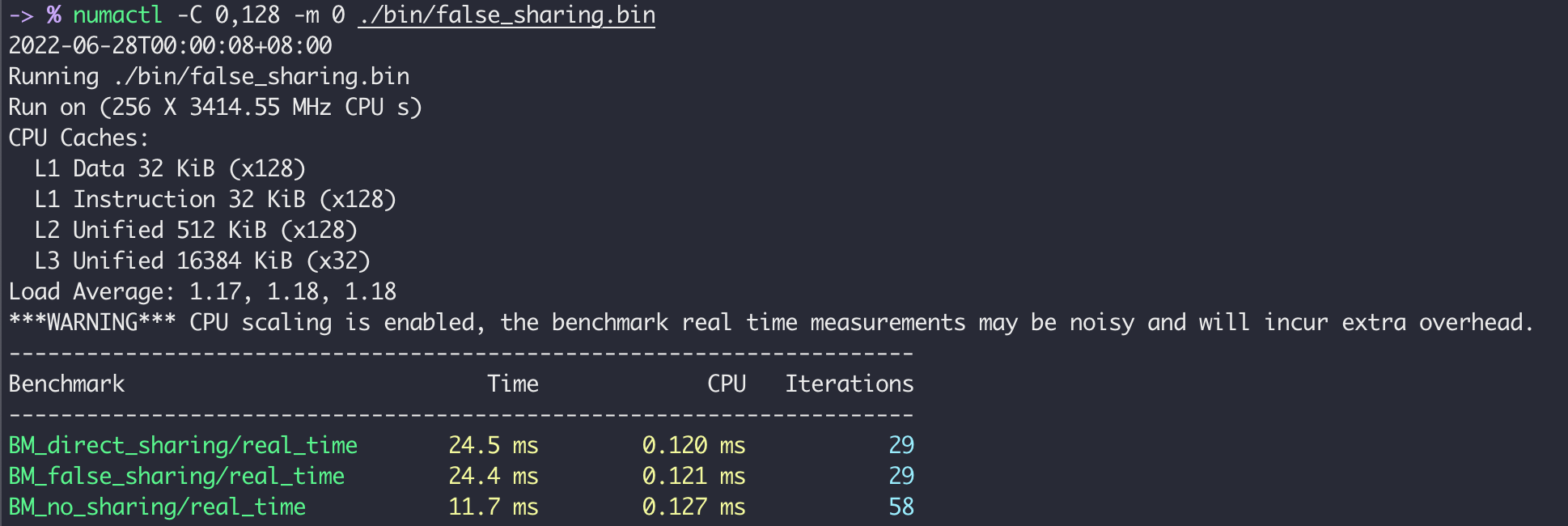
If we run 4 threads in 4 different physical cores within the same NUMA node, the result is:
 As we can see, the third no sharing setting gets performance gain, but the first two settings have nearly double elapsed time compared with
As we can see, the third no sharing setting gets performance gain, but the first two settings have nearly double elapsed time compared with 0,128.
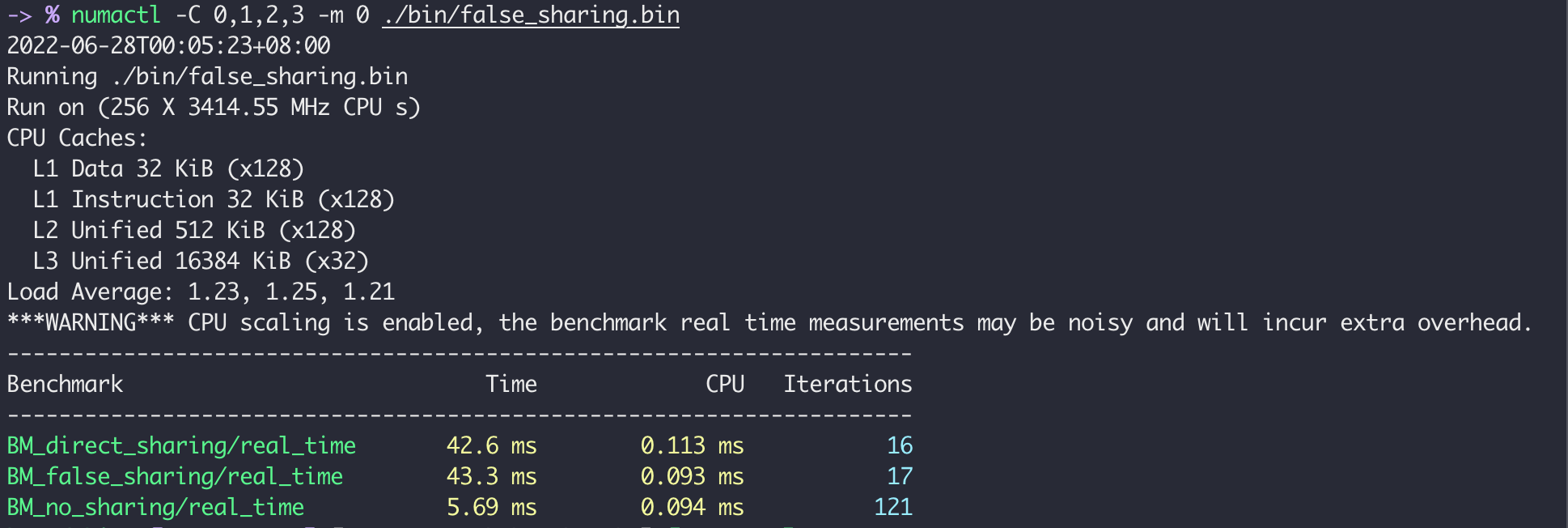
If we distribute the 4 threads into 2 different physical cores within one NUMA node, the result is:
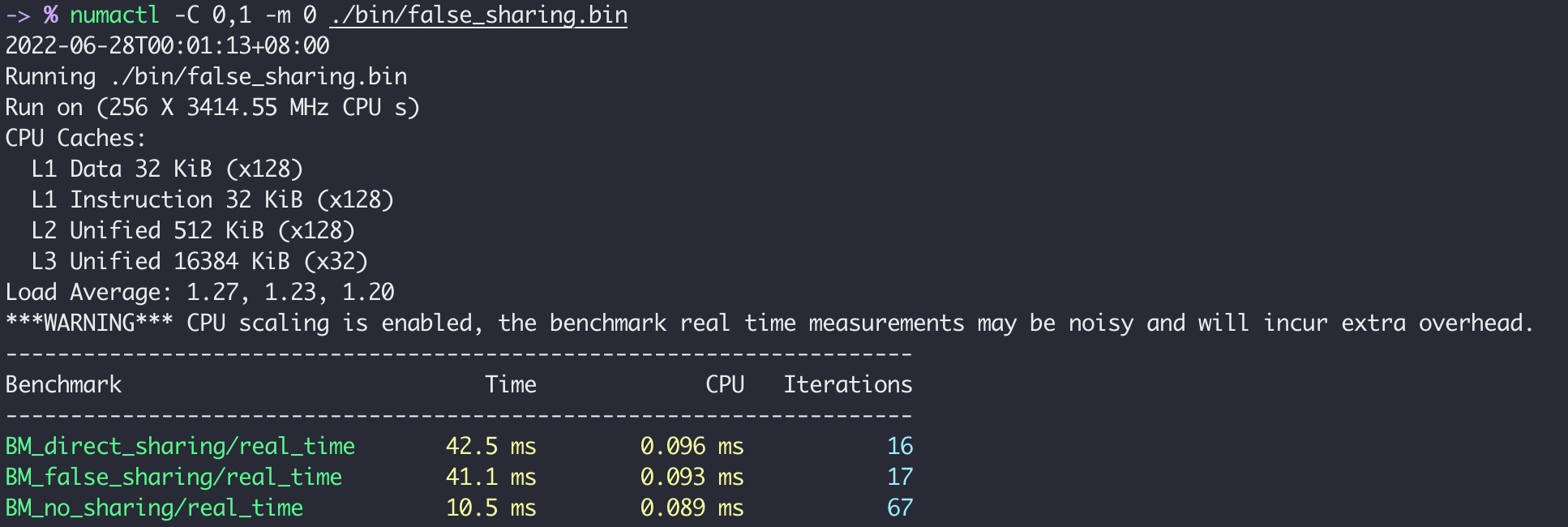 The data could not be shared between different physical cores so the elapsed time of the first two sharing settings doubles compared to the
The data could not be shared between different physical cores so the elapsed time of the first two sharing settings doubles compared to the 0,128 scenario.
And if we run the 4 threads in 2 physical cores in different NUMA nodes, the no sharing setting suffers because of the inter-NUMA memory access.