What is First Touch
The first touch policy means the memory pages will not be allocated instantly once they were declared (by calling malloc). The physical page is assigned to the virtual page ONLY after the address is first accessed (read or write) by one thread.
#include <stdlib.h>
void foo() {
// Lazy allocate
void *data = (void *)malloc(sizeof(char) * 4 * 1024);
// Allocate page on physical memory once the address is accessed
data[0] = 1;
}The first touch may lead to performance issue on NUMA platforms (and maybe SNC architecture as well, I’m not quite sure). If the allocated physical page and the work thread are not in the same NUMA node, the memory access entails extra inter-chip communication (through QPI).
Validate First Touch Performance Issue
Here I write a simple microbenchmark to demonstrate the impact of first touch allocation policy based on OpenMP. The process spawns a OpenMP team to add a constant value to each element in a large array:
auto start = std::chrono::high_resolution_clock::now();
#pragma omp parallel for schedule(static) num_threads(4)
for (size_t i = 0; i < n; ++i) {
data[i] += 42;
}
auto end = std::chrono::high_resolution_clock::now();
auto elapsed_seconds =
std::chrono::duration_cast<std::chrono::duration<double>>(end - start);The only difference between the two versions is how the memory is initialized:
# First touch
#pragma omp parallel for schedule(static) num_threads(4)
for (size_t i = 0; i < n; ++i) {
data[i] = i;
}
# Non first touch
for (size_t i = 0; i < n; ++i) {
data[i] = i;
}More specifically, the first version that utilizes first touch policy by forks 4 threads to initialize the newly-allocated array. Therefore every thread will obtain a slice of the array in its local memory. On the otherhand, the latter version only use single thread to initialize the array, thus the entire array locates in memory attached to the master thread.
Since we specify OpenMP runtime to use static scheduling strategy, we assume that the thread which initializes the data will acquire and get assigned with the same slice of the array. Conversely for the second version, data accesses from threads locating in different NUMA nodes from the master thread require extra transportation since the data is first touched by the (single) master thread.
Note that the measured consuming time is the duration elapsed between start and end of the calculating region. The memory allocation is not included.
Results
The code is available at this repository. A plot drawn from running logs is shown below:
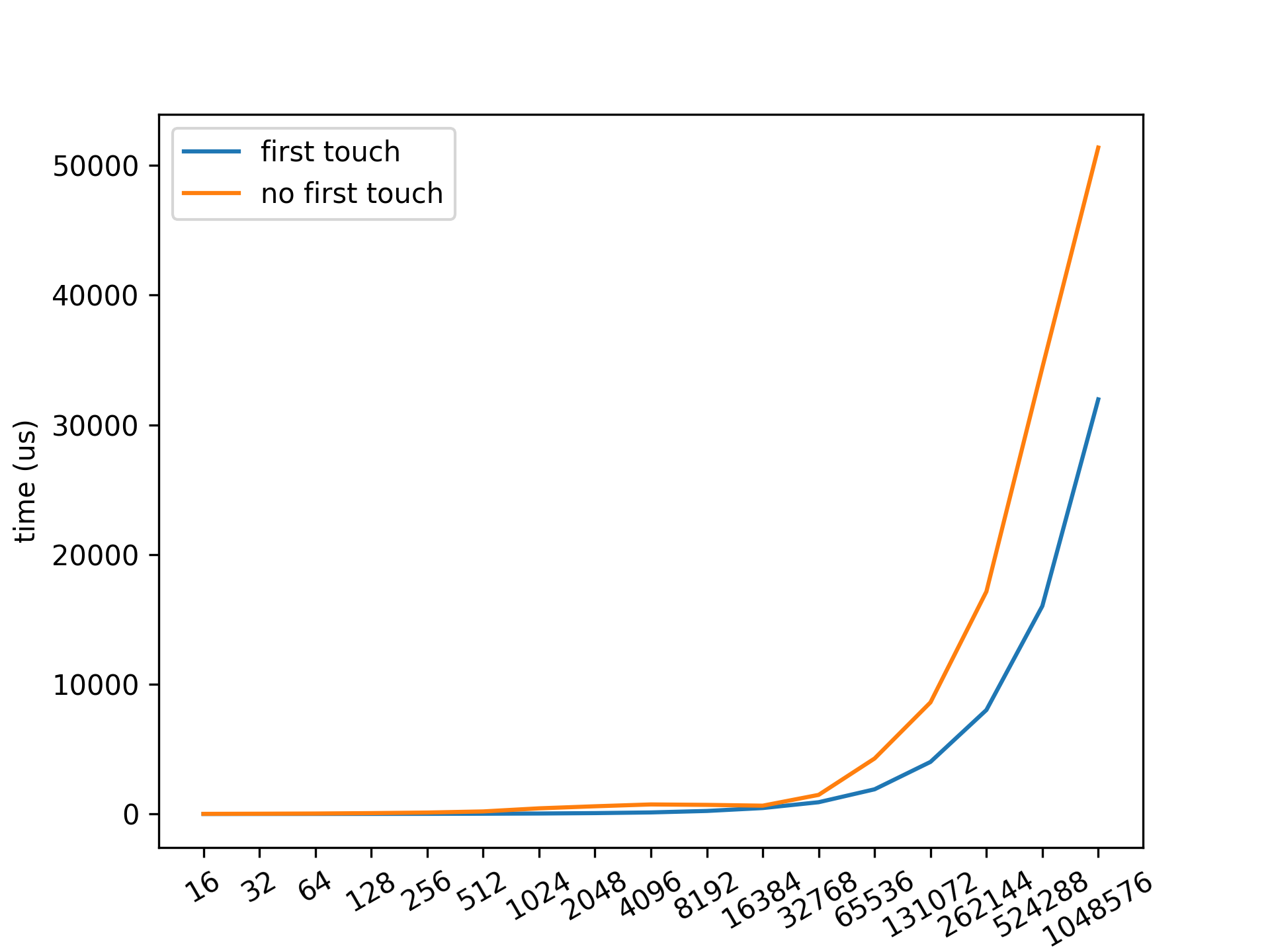
As we can see, the elapsed time consumed by non first-touch policy threads is more than those with first touch policy. As the data size increases, the gap between the policies increases as well.
To sum up, when programming, initialize data via the thread who will use the corresponding data later.