There are various approaches to categorize deep learning parallelisms:
- data parallelism
- model parallelism
- pipeline parallelism
- tensor parallelism
We tend to categorize existing parallel methods into two types:
- inter-operation: MP, PP
- intra-operation: DP, TP There may be other approaches other than the above four. But they can still be attributed into one of the two taxonomies.
Papers
Pipelining Model
-
[NeuralIPS ‘19] GPipe: efficient training of giant neural networks using pipeline parallelism
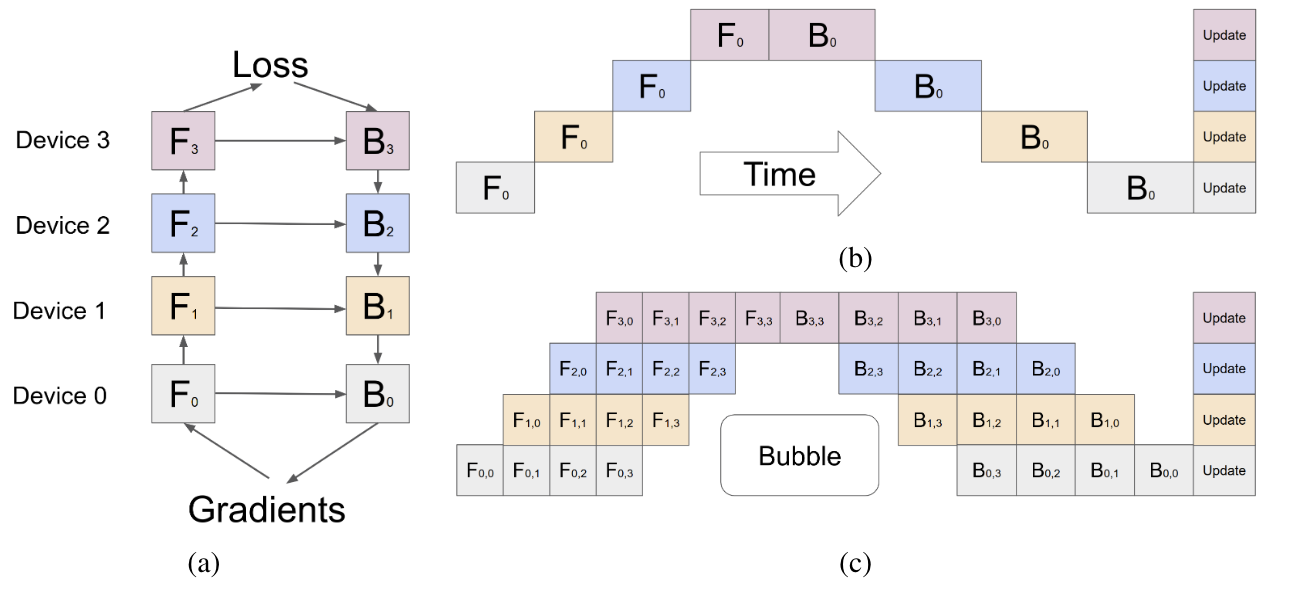 Group model layers into partitions, then assign each partition to different accelerators.
Forward and backward stages are pipelined among partitions, while P2P communication is required at partition boundaries.
There are two design dimension: # micro-batches and pipeline stages (namely, # accelerators).
Group model layers into partitions, then assign each partition to different accelerators.
Forward and backward stages are pipelined among partitions, while P2P communication is required at partition boundaries.
There are two design dimension: # micro-batches and pipeline stages (namely, # accelerators).- [SOSP ‘19] PipeDream: generalized pipeline parallelism for DNN training
Mitigate Memory Bottleneck
- [HPCA ‘23] MPress: Democratizing Billion-Scale Model Training on Multi-GPU Servers via Memory-Saving Inter-Operator Parallelism
- [ASPLOS ‘23] Mobius: Fine Tuning Large-Scale Models on Commodity GPU Servers
MoE
- [arXiv ‘24] MoE-Infinity: Activation-Aware Expert Offloading for Efficient MoE Serving Record sequence-level activation history as the expert activation matrix (ECM) and exploit the similarity of activated experts across sequences to prefetch/cache experts in GPU VRAM.